
Blog Title: Beyond the Embedding: Why Vectorless RAG and PageIndex are Transforming Document Intelligence
The AI world has a new favorite mantra: "Similarity is not relevance." For years, Retrieval-Augmented Generation (RAG) has relied almost exclusively on Vector-based retrieval. We chunked our data, turned it into high-dimensional math (embeddings), and stored it in vector databases. It worked—until we hit complex, structured documents like 200-page financial reports or legal contracts.
Today, a new contender called Vectorless RAG—led by the trending PageIndex framework—is flipping the script. It moves away from mathematical "vibes" and toward logical reasoning.
1. The Standard: Vector-Based RAG
Traditional RAG treats a document like a bag of marbles. You break it into small chunks, embed them, and find the "closest" marbles to your query using cosine similarity.
- The Strength: Excellent for searching across massive, unstructured datasets (e.g., "Find all mentions of 'sustainability' across 10,000 emails").
- The Weakness: It is "structure-blind." If a critical piece of data is split between Chunk A and Chunk B, the model might only retrieve one, losing the context. It also struggles with "multi-hop" questions where the answer requires connecting Section 1.2 to Appendix C.
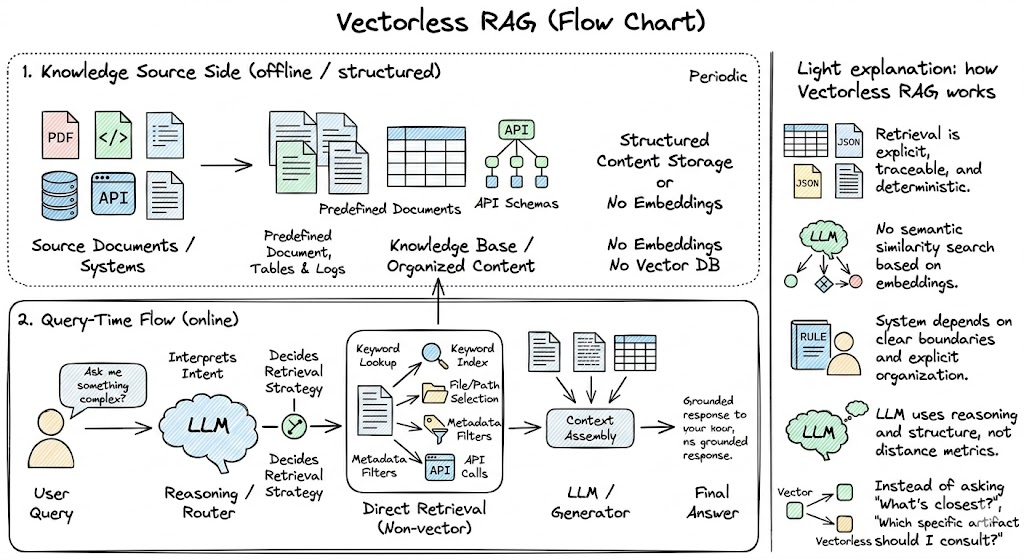
2. The Challenger: Vectorless RAG (PageIndex)
PageIndex (developed by Vectify AI) introduces a "Reasoning-Based" retrieval model. Instead of converting text into vectors, it preserves the document’s natural hierarchy.
 Explore PageIndex: https://pageindex.ai/blog/pageindex-intro
Explore PageIndex: https://pageindex.ai/blog/pageindex-intro
How PageIndex Works:
- Structural Tree Indexing: Instead of arbitrary 500-token chunks, PageIndex builds a Hierarchical Tree. Think of it as a smart Table of Contents where every node (Chapter -> Section -> Paragraph) has its own LLM-generated summary.
- Agentic Navigation: When you ask a question, the LLM doesn't look for similar vectors. It acts as an agent that "reads" the top-level summaries, decides which "branch" of the tree likely contains the answer, and navigates down to the specific leaf node.
- Context-Aware Extraction: It retrieves only the precise nodes needed, maintaining the logical flow of the original document.
The Performance Gap
In recent benchmarks like FinanceBench, traditional vector RAG often hovers around 50% accuracy on complex filings. PageIndex has reportedly achieved up to 98.7%, largely because it can follow cross-references (e.g., "See footnote 4") that vector search simply ignores.
3. When to Use Which?
Use Vector-Based RAG when:
- You are searching across thousands of different documents.
- You need sub-second response times for a customer-facing chatbot.
- Your data is conversational or unstructured (like Slack logs).
Use PageIndex (Vectorless) when:
- You are analyzing high-stakes documents (Legal, Medical, Financial).
- Precision is non-negotiable, and you need the LLM to cite exactly where it found the info.
- The document has a clear internal structure (Manuals, 10-K Reports, Academic Papers).
The Verdict: The Future is Hybrid
We aren't seeing the death of vector databases. Instead, we are entering an era of Hybrid RAG.
Imagine a system where Vector Search identifies the top 3 relevant documents from a library of millions, and then PageIndex takes over to perform a surgical, reasoning-based "deep dive" into those specific documents.
By combining mathematical scale with logical reasoning, we can finally build AI that doesn't just find information—it understands it.